‘Cluster Communication Latency' by Manolis Katevenis
Stamatis Vassiliadis Symposium
Title: Cluster Communication Latency: towards approaching the Minimum Hardware Limits, on Low-Power Platforms
Speaker: Manolis Katevenis, FORTH-ICS and University of Crete, Greece
Slides: http://samos-conference.com/Resources...
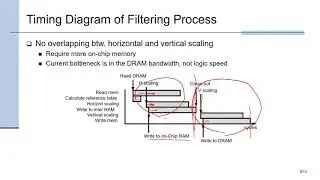
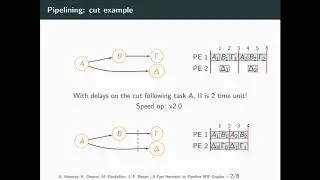
Abstract: Cluster computing is a necessity for High Performance Computing (HPC) beyond the scale reachable by hardware cache coherence (the scale of a single "node"). Unfortunately, still today, inter-node communication in many clusters (other than expensive and power-hungry ones) is based on old-time hardware and software architectures, dating back to when such communication was viewed as "I/O rather than memory" and hence non-latency-critical. Although we know how to reduce latency when accessing "memory", the majority of low-cost and low-power commercial platforms, still today, do not care to do this when "performing I/O". Within a series of 5 projects, we are working towards fixing this problem, for modern energy-efficient ARM-based platforms, which hold great promise for Data Centers and HPC; this talk will present a summary of our efforts, under the general name "UNIMEM", and in particular: To reduce latency and energy consumption during communication, we need to avoid interrupts and system calls and reduce the number of data copies. Single-word (e.g. control/sync) communication can be efficiently performed via remote load/store instructions, provided there is a Global Address Space (GAS). Block-data communication is efficiently performed via remote DMA (RDMA), where again a GAS is required in order to save a data copy at the remote node. DMA and I/O have to be cache-coherent (not always provided, even today); at the arrival node, it is desirable to be able to control cache-allocation or not. RDMA initiation without system call requires virtual address arguments, which we translate using the IOMMU (aka System MMU). For scalability, address translation should be performed at the destination, i.e. we advocate a 64-bit Global Virtual Address Space (GVAS); coupled with inter-node (process) protection, this requires 80- to 96-bits within network packets. These are incompatible with current MMU's that always translate load/store addresses at the issuer, and with current DMA engines and I/O maps that only handle 40 or 48 address bits. Allowing RDMA between arbitrary (user) memory areas (as opposed to registered and pinned ones, only), without any extra data copies, requires RDMA to tolerate and recover from page faults. RDMA completion detection is tricky, especially in the presence of multipath routing: it requires hardware support at the receiver NI, in order to avoid one network round-trip, and mailboxes (hardware queues) for notification without interrupts. Finally, when trying to have MPI communicate with zero-copy and single-network-trip latency, we would like either the receive call to accept data at system-selected address, contrary to the current standard, or send-receive matching to be performed at the sender, which cannot be done in the case of MPI_ANY_SOURCE.


![SLAP HOUSE MAFIA, DKSH, FLOW - BALENCIAGA (REMIX) [NO COPYRIGHT] Car Music 2021](https://images.mixrolikus.cc/video/eJIinxdOOZI)