A Quantitative Study of Locality in GPU Caches
Sohan Lal and Ben Juurlink
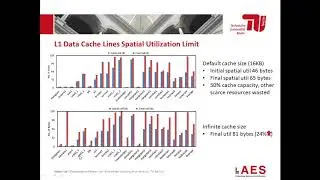
Traditionally, GPUs only had programmer-managed caches. The advent of hardware-managed caches accelerated the use of GPUs for general-purpose computing. However, as GPU caches are shared by thousands of threads, they are usually a victim of contention and can suffer from thrashing and high miss rate, in particular, for memorydivergent workloads. As data locality is crucial for performance, there have been several efforts focusing on exploiting data locality in GPUs. However, there is a lack of quantitative analysis of data locality and data reuse in GPUs. In this paper, we quantitatively study the data locality and its limits in GPUs. We observe that data locality is much higher than exploited by current GPUs. We show that, on the one hand, the low spatial utilization of cache lines justifies the use of demand-fetched caches. On the other hand, the much higher actual spatial utilization of cache lines shows the lost spatial locality and presents opportunities for further optimizing the cache design.


![SLAP HOUSE MAFIA, DKSH, FLOW - BALENCIAGA (REMIX) [NO COPYRIGHT] Car Music 2021](https://images.mixrolikus.cc/video/eJIinxdOOZI)