RAG Optimization: A Practical Overview for Improving Retrieval Augmented Generation
Optimizing retrieval augmented generation makes large language models more powerful and reliable, but off-the-shelf components yield lackluster results.
Snorkel AI Principal Research Scientist Chris Glaze explains how to fine-tune multiple parts of rag systems—from document chunking to embedding models and to data enrichment—to ensure that LLM systems use their model's context window as effectively as possible.
See more videos about RAG here: • RAG: Building enterprise ready retrie...
Timestamps:
00:00 Introduction to RAG Optimization
01:36 Importance of Retrieval in RAG
02:38 Document Chunking Process
03:33 Techniques for Chunking Documents
08:32 Metadata Extraction and Its Value
10:02 Approaches to Information Extraction
11:06 Overview of Embeddings and Retrieval Models
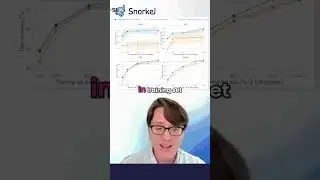
12:20 Fine-Tuning Embeddings for Retrieval
13:14 Baseline Evaluation of Embedding Models
14:29 Data Development for Fine-Tuning
17:18 Creating a Training Set
18:40 Utilizing Relevant Scores
20:44 Summary of RAG Pipeline Optimization
#enterpriseai #rag #machinelearning