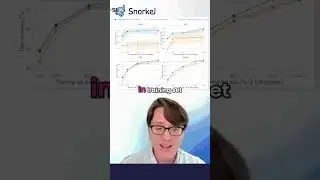
Three Ways to Evaluate LLMs
Most LLM evaluation falls into three buckets:
Open source evaluations and metrics.
LLM as judge.
Human annotation—whether internal or outsourced.
Snorkel AI founding engineer Vincent Sunn Chen walks through the advantages and drawbacks of each of these approaches.
This video is an excerpt from a longer webinar. See the full event here: • How to Evaluate LLM Performance for Domain...
#largelanguagemodels #evaluation #annotation


![El Cascabel [Son Jarocho] | The Mesoamerican Orchestra](https://images.mixrolikus.cc/video/O0Ln-DnBMGk)