4 Ways to Align LLMs: RLHF, DPO, KTO, and ORPO
Enterprises must align large language models to make them work on their specific domain, task, and communication style. Snorkel AI researcher Tom Walshe walks through four separate LLM alignment methods:
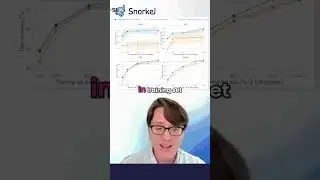
Reinforcement learning with human feedback (RLHF)
Direct preference optimization (DPO)
Odds-ratio preference optimization (ORPO)
Kahneman-Tversky Optimization (KTO)
Each of these approaches has advantages and drawbacks.
This video is an excerpt from a longer webinar. See it here: • How to Fine-Tune LLMs to Perform Specializ...
#largelanguagemodels #alignment #orpo


![El Cascabel [Son Jarocho] | The Mesoamerican Orchestra](https://images.mixrolikus.cc/video/O0Ln-DnBMGk)