How to Optimize RAG Pipelines for Domain- and Enterprise-Specific Tasks
Learn how to build and optimize Retrieval Augmented Generation (RAG) pipelines for accurate, reliable, and efficient LLM-powered applications. This webinar dives deep into the challenges of RAG and provides practical solutions.
Snorkel AI's Shane Johnson (product) and Haley Massa (ML solutions engineer) guide the viewer through a basic overview of how RAG systems work, followed by how users can improve them in the Snorkel Flow AI data development platform.
In this video, you'll discover how to:
Master semantic document chunking and embedding techniques.
Fine-tune your RAG pipeline for optimal performance.
Leverage Snorkel Flow to accelerate RAG development.
Don't let retrieval errors hold back your AI projects. Watch now to gain the knowledge and tools to build world-class RAG systems!
Key moments:
Timestamps:
00:00 Introduction
00:22 Key Takeaways
01:35 Importance of Specialization
02:27 Improving RAG Pipelines
02:51 Chunking Correctness
03:02 Retrieval Accuracy
03:10 Context Window Utilization
03:17 Importance of Data
04:13 Focus on Retrieval
04:40 Pre-Retrieval Process
05:36 Retrieval Process
06:42 Chunking Optimization
10:27 Adaptive Chunking
12:11 Document Enrichment
13:08 Example of Information Extraction
15:10 Embedding Model Overview
16:37 Fine-Tuning the Embedding Model
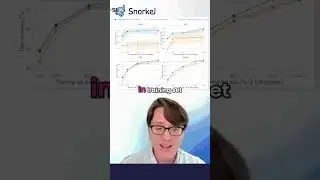
18:37 Visualizing Embedding Model Performance
20:49 Context Window Optimization
23:24 AI Data Development
24:02 Snorkel Flow Overview
25:01 Human-in-the-Loop Evaluation
27:15 Collaboration with SMEs
31:22 Transition to Demo
31:49 Demo Overview
32:30 Case Study: Banking LLM System
33:57 Pre-Production Environment Testing
36:15 Manual Annotation in Snorkel Flow
40:09 RAG Enrichment Process
49:14 Key Learnings
51:23 Q&A Session
55:38 Conclusion
#RAG #LLM #enterpriseai


![El Cascabel [Son Jarocho] | The Mesoamerican Orchestra](https://images.mixrolikus.cc/video/O0Ln-DnBMGk)