How to Fine-Tune LLMs to Perform Specialized Tasks Accurately
LLMs must be fine-tuned and aligned on domain-specific knowledge before they can accurately and reliably perform specialized tasks within the enterprise.
However, the key to transforming foundation models such as Meta's Llama 3 into specialized LLMs is high-quality training data.
In this webinar, Snorkel AI's experts provide an overview of fine-tuning methods such as DPO, ORPO, and SPIN, explain how to curate high-quality instruction and preference data 10-100x faster (and at scale), and give a demo showing how we fine-tune, align and evaluate LLMs.
Watch this webinar to learn more about:
Curating high-quality training data 10-100x faster
Emerging LLM fine-tuning and alignment methods
Evaluating LLM accuracy for production deployment
See more videos from Snorkel AI here: / @snorkelai
See more Snorkel Flow demos here: • Snorkel Flow Demos: See How it Works!
See more videos about Enterprise AI here: • Enterprise AI: Unlocking the Power of AI f...
Timestamps:
00:00 Introduction
01:11 Fine-tuning Overview
01:55 When and Why to Fine-tune
02:47 Fine-tuning Techniques
06:13 Data Considerations
07:22 Supervised Fine-tuning
09:40 Reinforcement Learning Techniques
12:58 Recent Methods in Fine-tuning
14:05 Lessons Learned
15:11 Data Requirements for Fine-tuning
16:21 Programmatic Data Labeling
19:17 Demo Introduction
23:56 Demo of Jarvis
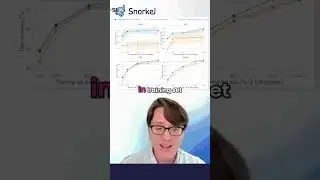
37:53 Summary of Findings
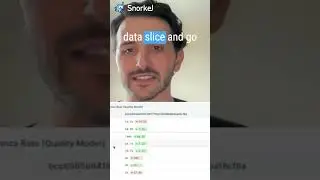
38:38 Future Directions and Data Slices
43:41 Q&A Session
51:15 Conclusion
#enterpriseai #finetuning #largelanguagemodels


![El Cascabel [Son Jarocho] | The Mesoamerican Orchestra](https://images.mixrolikus.cc/video/O0Ln-DnBMGk)