How to tune RAG implementations for specialized enterprise tasks
RAG (retrieval-augmented generation) is the de-facto standard for grounding LLM-powered AI applications. However, prompt engineering and supplemental context is not enough to perform domain-specific tasks with precision.
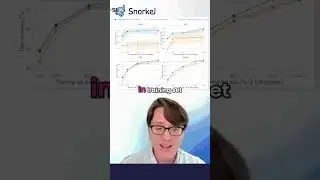
Enterprise use cases which depend on subject matter expertise and demand high accuracy require a fine-tuned RAG architecture—from chunking and embedding to reranking and context-window optimization.
In this webinar, Snorkel AI co-founder and CEO Alex Ratner shares insights into emerging AI practices and the future of enterprise adoption.
In addition, Principal Research Scientist Chris Glaze and Generative AI Product Lead Marty Moesta discuss the latest research in RAG tuning and demonstrate how to apply it via AI data development techniques.
Join us and learn how to:
Optimize RAG components to increase accuracy and precision
Apply AI data development techniques to improve model accuracy
Accelerate the delivery of production RAG implementations
Timestamps:
00:00 Introduction
01:11 Speaker Introductions
02:40 Data-Centric AI Overview
03:53 Understanding Retrieval Augmented Generation (RAG)
05:16 The Importance of Fine-Tuning
11:17 Strategies for Optimizing RAG Systems
13:30 RAG Optimization Process
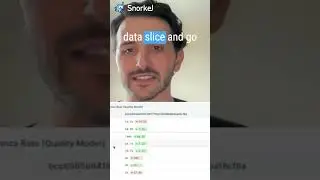
35:45 Live Demo of Snorkel Flow
46:39 Techniques for Enriching RAG Pipelines
52:54 Q&A Session
#rag #enterpriseai #largelanguagemodels