How to Build A Statistical Framework On A Method
Forecasting with exponential smoothing is a book focused on a niche topic. I
picked up this book because I like Rob Hyman's other papers and books. There is
also another familiar name, Keith Ord, who wrote a fantastic practical book on
business forecasting. If you are interested in this book, check out my
video review.
Exponential smoothing was formulated without a statistical
framework. It has been a successful forecasting algorithm and practice for
decades.
Why fuse about the lack of statistical framework in the back end? The
authors expound on the utility of having a statistical framework for
exponential smoothing. I think that if you are interested in writing forecasting
software, teaching exponential smoothing, or getting a deeper understanding of
forecasting methodology, this is the book for you. But I think there is more to
this book than just being a passive observer of the unfolding of a statistical
framework. I think this book is an example of how good forecasters think
critically. If you pay attention, you may walk away with some thoughts on how to
add statistical frameworks to other algorithms.
One thing I appreciated was
the recursive calculation tables. It was nice to be able to compare and contrast
models with different trend and seasonality parameters and how to factor in
errors that were additive or multiplicative. Then I could compare
state space tables against the recursive formulas to see what the authors were
bringing to the table. I like this section on MASE, which is mean absolute
scaled error. It is clear that this is an important metric for modern
forecasting, sections and with exercises.
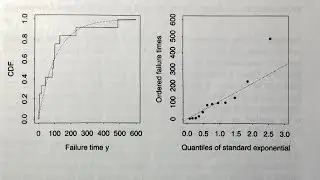
When you set exponential smoothing on a
statistical framework, you get prediction distributions for free. Authors
dedicate a full chapter on how these prediction distributions are generated.
One topic that is sometimes glossed over is how to handle time series with
multiple seasonal patterns. They offer some advice for practitioners on how to
approach this problem within the scope of exponential smoothing.
I really enjoyed
their section on count data. It is a common problem in firms but rarely
addressed in books and literature. One thing I really appreciated was the table
they had comparing forecast performance of various models. I learned how to
compare models a little better from this table alone. First, they used MASE as a
metric. Second, they compared many models. Third, they reported the mean, median
and standard deviation. Fourth, they had a benchmark performance of a model they
called Z. Z was simply predicting zero always. Those performance was not good. It
was nice to have a sense of what kind of error a simple assumption like that would
work out to be. Part four is the section I have revisited the most. It is hard for
practitioners to really know what other forecasters are doing in other
companies. Most work is considered IP. That makes sense and I also respect that as
well. Because ideas are not always shared completely across firms, the
applications, sections and books are sometimes the best tutor you can have for
real business scenarios. Thanks for watching and we'll see you next time.
XVZFTUBE ONLINE:
🕸️ https://xvzf.bearblog.dev/tools/
📁 GitHub: https://github.com/xvzftube
FREE AND OPEN SOURCE SOFTWARE THAT I CURRENTLY USE:
📽️ FFmpeg|LGPL: ............. https://ffmpeg.org/
🎵 Audacity|GPL: ............ https://www.audacityteam.org/
🗒️ Neovim|Apache 2.0: ....... https://neovim.io/
R R|MIT: ................... https://www.r-project.org/
🐍 Python|Python: ........... https://www.python.org/
🪶 SQLite|Public Domain: .... https://www.sqlite.org/index.html
🦆 DuckDB|MIT: .............. https://duckdb.org/
🍥 Debian|GPL: .............. https://www.debian.org/



















![Lightning-Fast Setup: Get VS Code & Python Up and Running in No Time [Windows | 2023]!](https://images.mixrolikus.cc/video/EdxAUXXGB_M)