Accelerating Machine Learning and Deep Learning At Scale With Apache Spark: talk by Ziya Ma
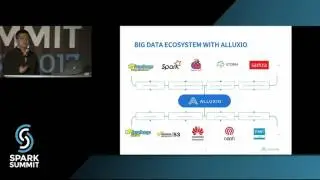
Deep learning is a fast growing subset of machine learning. There is an emerging trend to conduct deep learning in the same cluster along with existing data processing pipelines to support feature engineering and traditional machine learning. As the leading framework for Distributed ML, we believe that the addition of deep learning to the super-popular Spark framework is important, because it allows Spark developers to perform a range of data analysis tasks within a single framework that helps avoid the complexity inherent in using multiple frameworks and libraries. As one of the early and top contributors to Apache Spark, Intel is thrilled to share with the community a big deal contribution to open source Spark…”BigDL” -… A distributed deep Learning framework organically built on Big Data (Apache Spark) platform. It combines the benefits of “high performance computing” and “Big Data” architecture for rich deep learning support. With BigDL on Spark, customers can eliminate large volume of unnecessary dataset transfer between separate systems, eliminate separate HW clusters and move towards a CPU cluster, reduce system complexity and the latency for end-to-end learning. Ultimately, customers can achieve better scale, higher resource utilization, ease of use/development, and better TCO. Feature parity with Caffe and Torch, significant performance boost when combined with Intel’s Math Kernel Library (MKL), scale-out, fault tolerance, elasticity and dynamic resource sharing are some of the prominent features of BigDL.
BigDL open source project will be launched at the 2017 Spark Summit East and this keynote will help spotlight this new contribution and benefits to the Spark developer community and encourage their wide contribution and collaboration. We will also showcase some real world applications of Big DL from early customers’ adoption.