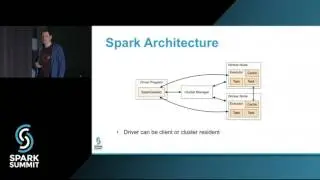
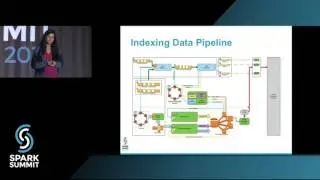
Spark Streaming as a Service with Kafka and YARN: Spark Summit East talk by Jim Dowling
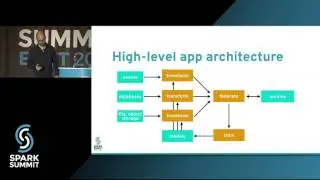
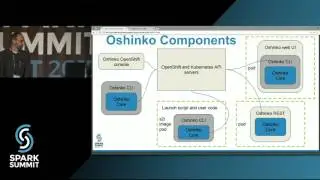
Since April 2016, Spark-as-a-service has been available to researchers in Sweden from the Swedish ICT SICS Data Center at www.hops.site. Researchers work in an entirely UI-driven environment on a platform built with only open-source software.
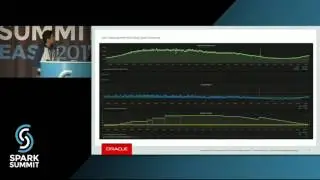
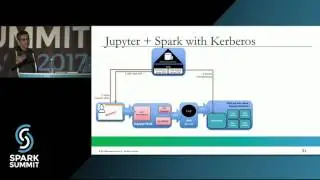
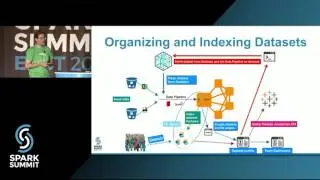
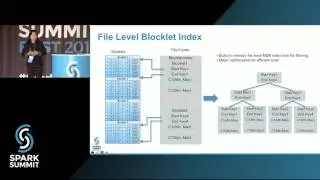
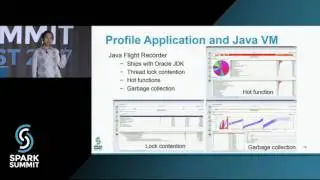
Spark applications can be either deployed as jobs (batch or streaming) or written and run directly from Apache Zeppelin. Spark applications are run within a project on a YARN cluster with the novel property that Spark applications are metered and charged to projects. Projects are also securely isolated from each other and include support for project-specific Kafka topics. That is, Kafka topics are protected from access by users that are not members of the project. In this talk we will discuss the challenges in building multi-tenant Spark streaming applications on YARN that are metered and easy-to-debug. We show how we use the ELK stack (Elasticsearch, Logstash, and Kibana) for logging and debugging running Spark streaming applications, how we use Graphana and Graphite for monitoring Spark streaming applications, and how users can debug and optimize terminated Spark Streaming jobs using Dr Elephant. We will also discuss the experiences of our users (over 120 users as of Sept 2016): how they manage their Kafka topics and quotas, patterns for how users share topics between projects, and our novel solutions for helping researchers debug and optimize Spark applications.
To conclude, we will also give an overview on our course ID2223 on Large Scale Learning and Deep Learning, in which 60 students designed and ran SparkML applications on the platform.