Fusing Apache Spark and Lucene for Near Realtime Predictive Model Building (Deb Das)
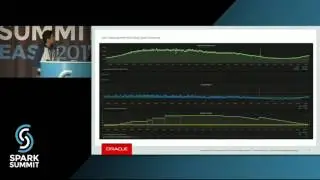
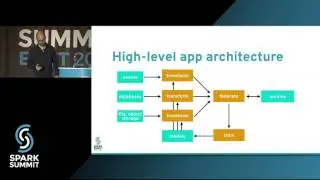
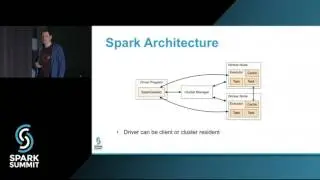
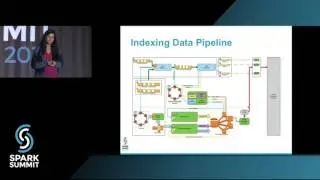
Spark SQL and Mllib are optimized for running feature extraction and machine learning algorithms on large columnar datasets through full scan. However when dealing with document datasets where the features are represented as variable number of columns in each document and use-cases demand searching over columns to retrieve documents and generate machine learning models on the documents retrieved in near realtime, a close integration within Spark and Lucene was needed. We introduced LuceneDAO (data access object) that supports building distributed lucene shards from dataframe and save the shards to HDFS for query processors like SolrCloud. Lucene shards maintain the document-term view for search and vector space representation for machine learning pipelines. We used Spark as our distributed query processing engine where each query is represented as boolean combination over terms. LuceneDAO is used to load the shards to Spark executors and power sub-second distributed document retrieval for the queries. We developed Spark Mllib based estimators for classification and recommendation pipelines and use the vector space representation to train, cross-validate and score models to power synchronous and asynchronous APIs. Our synchronous API uses Spark-as-a-Service while our asynchronous API uses kafka, spark streaming and HBase for maintaining job status and results. In this talk we will demonstrate LuceneDAO write and read performance on millions of documents with 1M+ terms. We will show algorithmic details of our model building pipelines that are employed for performance optimization and demonstrate latency of the APIs on a suite of queries generated over 1M+ terms. Key takeaways from the talk will be a thorough understanding of how to make Lucene powered search a first class citizen to build interactive machine learning pipelines using Spark Mllib.



![Thanos vs Thor | Avengers: Sonsuzluk Savaşı (2018) | Türkçe Dublaj [1080p]](https://images.mixrolikus.cc/video/agVfb0KyT00)