Storytelling using LangChain and Hugging Face! | Convert an Image to an Audio Story!
In this video, we demo a project by which you can make an audio story out of a single input image! We do this using LangChain and a number of FREE Hugging Face models. Specifically, we use the open-source Falcon model as our Large Language Model (LLM) to generate a story from a scenario. To get the scenario, we pass our input image to an image captioning model from Hugging Face and use the generated caption as our scenario. Finally, we use a text to speech model from Hugging Face to convert our story to speech to get an audio story!
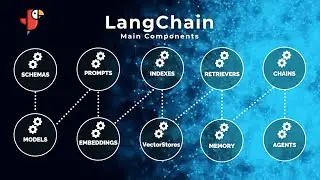
LangChain is an open-source framework that enables developers to build applications powered by large language models (LLMs). LLMs are deep-learning models that have been pre-trained on vast amounts of data and can generate responses to user queries, such as answering questions or creating images from text-based prompts. LangChain provides a unified interface and standardized framework for working with LLMs, making it easier to integrate them into applications.
Hugging Face is a French-American company based in New York City that has developed a platform and tools for building applications using machine learning. It is primarily known for its transformers library, which is designed for natural language processing (NLP) applications. The company's platform allows users to share machine learning models, datasets, and showcase their work.
#langchain #huggingface #ai #largelanguagemodels #llm #falcon #chatgpt #gpt #gpt3 #gpt4 #chatbot #text2speech #image2text #caption #api #generativeai #deeplearning #nlp




![Bartosz Domiczek - D2 Talks #33 [interviewed by Fabio Palvelli]](https://images.mixrolikus.cc/video/_sQkFBCvblE)