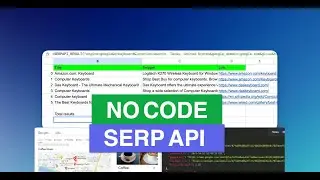
How to scrape dynamic web pages #2 |
Illia and Dima are working at SerpApi. This time, Illia will be the guest and share knowledge about extracting data from dynamic web pages (https://en.wikipedia.org/wiki/Dynamic.... As known as, single page apps, SSG content, etc.
Chapters
00:00 Hello
00:07 Introduction
00:58 What is the hardest part of extracting data and bypassing blocking in Illia experience
01:31:42 Question: steps to learn dev tools for web scraping
01:34:54 Preview of a question from aliayarpy: CSS vs XPath
01:41:31 What is better to select nodes in HTML: CSS selectors or XPath queries? (Question from viewer aliayarpy)
01:45:30 :has(text()=) from CSS4 can be improved (comment from viewer Kagermanov)
01:47:45 Why industry tend to use CSS selectors instead of XPath? (Question from viewer aliayarpy)
01:47:45 CSS selectors are more concise when selecting class names
01:50:20 What is faster: CSS selectors or XPath queries?
01:52:12 Performance improvement in CSS selectors in Nokogiri
01:54:38 Sergii said "hi"
01:55:01 Illia's to-do: Render HTML in a browser runtime from the CLI
01:57:12 Bug in Google Images API: first 20 images are duplicated
01:57:58 Summary
---
#SerpApiPodcast is a podcast all about SERP data scraping. This is the episode number 5.
---
SerpApi provides the fast, easy, and complete API to scrape Google and other search engines: https://serpapi.com