Detecting anomalies using Isolation Trees: Practical Machine Learning
Production alerts are an important way in which engineers monitor the health of their services. The alerts are fired when important service metrics behave irregularly. An example would be a sudden spike in the number of errors or a crash in the number of running processes.
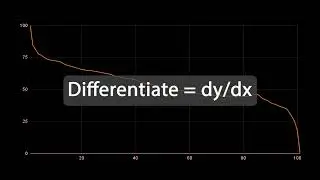
We design a system to allow important server metrics to be published, analysed and acted upon. The metrics are sent using sidecars in a service mesh. The metrics are then capped and run through machine learning algorithms like isolation trees to search for anomalies.
Service Mesh:
https://www.nginx.com/blog/what-is-a-...
Isolation forest:
https://towardsdatascience.com/outlie...
• Anomaly Detection: Algorithms, Explan...
References:
https://eng.uber.com/argos/
• Anomaly Detection: Increasing Classif...
https://machinelearningmastery.com/ar...
http://citeseerx.ist.psu.edu/viewdoc/...
https://towardsdatascience.com/machin...
https://jotterbach.github.io/2016/03/...
• Network Anomaly Detection and Root Ca...
http://rstudio-pubs-static.s3.amazona...
Preparing for design Interviews?
https://get.interviewready.io/
You can follow me on:
LinkedIn: / gaurav-sen-56b6a941
Twitter: / gkcs_
#AnomalyDetection #MachineLearning #IsolationTrees














![30 [Software Engineering] research papers you should read](https://images.mixrolikus.cc/video/kVP1qM9zgaA)










![20 AWS services you should know [as a Software Engineer]](https://images.mixrolikus.cc/video/tNbMyQGGyYM)